之前我们总结了 使用谷歌 Cloud Speech API 将语音转换为文字 的基本流程,然而那只是在命令行中使用 curl 实现的。这次我们将总结在 Python 中使用 Cloud Speech API 的方法。
配置 Python 开发环境
笔者使用的是树莓派(Debian)进行试验的,其他平台的配置方法可以在 这里 查找。
安装 Python
大多数 Linux 发行版都包含 Python。对于 Debian 和 Ubuntu,运行以下指令确保 Python 版本是最新的:
sudo apt update
sudo apt install python python-dev python3 python3-dev python-pip python3-pip
安装和使用 virtualenv
尽管这一步不是必须的,但强烈建议你使用 virtualenv。virtualenv 是一种创建独立 Python 环境的工具,可以将每个项目的依赖关系隔离开来。在虚拟环境下,你可以不必顾虑 python2 和 python3 的冲突;另外一个优势是可以直接将你的项目文件夹复制到其他机器上,文件夹内就包含了项目所依赖的软件包。
sudo apt install python-virtualenv
安装完成后,就可以在你的项目文件夹中创建一个虚拟环境。
cd 项目文件夹
virtualenv --python python3 env
使用 --python 标志来告诉 virtualenv 要使用哪个 Python 版本,这次试验将全程以 python3 环境进行。执行后会在 ` 项目文件夹 ` 内创建一个 env 文件夹。
创建完成后,你需要 “激活”virtualenv。激活 virtualenv 会告诉你的 shell 为 Python 使用 virtualenv 的路径。
source env/bin/activate
看到激活虚拟环境后,你就可以放心地安装软件包,并确信它们不会影响其他项目。

如果你想停止使用 virtualenv 并返回到全局 Python 环境,你可以关闭它:
deactivate
配置 Cloud Speech API 客户端库
我们假定你已经有合适的方法,能够使用谷歌服务,并且已经开始使用 Google 云平台。如果你有疑问,或许可以参考 这篇文章。
安装客户端库
如果你安装了 virtualenv,请确保激活了虚拟环境。
pip install --upgrade google-cloud-speech
值得一提的是,笔者使用的树莓派在安装进行到 Running setup.py bdist_wheel for grpcio ... 时停留了非常久(10 分钟以上),这属于正常现象,树莓派编译进行得很慢,需要耐心等待。
设置验证
从 ` 服务帐户 ` 下拉列表中选择 ` 新建服务帐户 ` 。输入合适的 ` 服务帐号名称 ` , ` 角色 ` 选择 Project → ` 所有者 ` 。 ` 密钥类型 ` 选择 JSON 。
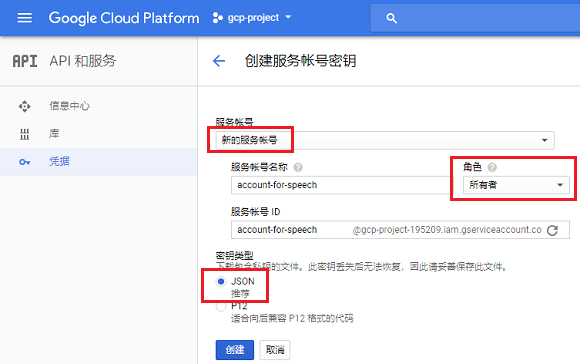
点击 ` 创建 ` 后,会开始下载包含密钥的 JSON 文件,请妥善保存。
最后,将环境变量 GOOGLE_APPLICATION_CREDENTIALS 设置为含密钥的 JSON 文件的文件路径,例如:
export GOOGLE_APPLICATION_CREDENTIALS="/home/pi/speech/speech-account.json"
请将 /home/pi/speech/speech-account.json 替换为你的 json 文件路径。
当然,直接输入上述命令设置的环境变量是临时的。一个比较实用的方法是在 ~/.bashrc 文件中设置环境,之后就不需要再手动设置了。
sudo nano ~/.bashrc
在文件末尾插入上述 export 命令,保存。
使用客户端库
下例给出了使用客户端库的方法。
import io
import os
# Imports the Google Cloud client library
from google.cloud import speech
from google.cloud.speech import enums
from google.cloud.speech import types
# Instantiates a client
client = speech.SpeechClient()
# The name of the audio file to transcribe
file_name = os.path.join(
os.path.dirname(__file__),
'voice.wav')
# Loads the audio into memory
with io.open(file_name, 'rb') as audio_file:
content = audio_file.read()
audio = types.RecognitionAudio(content=content)
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code='cmn-Hans-CN')
# Detects speech in the audio file
response = client.recognize(config, audio)
for result in response.results:
print几点说明:
file_name 给出了声音文件的路径。其中 os.path.dirname(__file__) 表示 py 代码所在文件夹的路径。故上例中声音文件是 py 代码相同目录下的 voice.wav 。
config 给出了声音文件的编码信息,Cloud Speech API 并不支持任意格式的声音文件,详细要求参见:AudioEncoding - Google Cloud Speech API 。
language_code='cmn-Hans-CN' 表示识别语言为中文普通话。常用的还有 American English ( en-US )、British English ( en-GB )、日本語 ( ja-JP )、廣東話( yue-Hant-HK )。更多语言支持可以在Language Support - Google Cloud Speech API 查询。
运行结果:

“Confidence” 是置信度,越接近 1 准确性越高。
小结
至此,Cloud Speech API 的使用总结就告一段落了,希望能对你有所帮助。这篇总结是参照着 Google Cloud Speech API 文档 写下的,如果有何纰漏恳请指出。
感谢你阅读文章!