在之前发布的 使用谷歌 Cloud Speech API 将语音转换为文字 一文中,我们实现了在控制台使用 curl 发送 post 请求,得到语音转文字的结果;而 在 Python 中使用谷歌 Cloud Speech API 将语音转换为文字 一文中,我们实现了安装 Cloud Speech API 客户端库,通过调用库函数得到语音转文字的结果。
如果你尝试过这两种方法,就会发现其实后者得到结果需要的时间要长一些(笔者使用这两种方法得到结果的耗时分别大约是 5 秒、7 秒)。那么,有没有办法在 python 中像第一种方法那样,使用 curl 命令发送 post 请求呢。当然是可行的,所以今天我们将介绍在 Python 中使用 Cloud Speech API 将语音转换为文字的另一种方案,另外这次我们将把音频文件编码为 base64 嵌入到 json 请求文件中,省去了上传声音文件到 Cloud Storage 的步骤。
相关说明之类的在上面两篇文章里已经写了很多,这边就直接贴代码。
- 使用 python3
import json
import urllib.request
import base64
# ①
api_url = "https://speech.googleapis.com/v1beta1/speech:syncrecognize?key = 你的 API 密钥"
audio_file = open('/home/pi/chat/test-speech/output.wav', 'rb')
audio_b64 = base64.b64encode(audio_file.read())
audio_b64str = audio_b64.decode() # ②
# print(type(audio_b64))
# print(type(audio_b64str))
audio_file.close()
# ③
voice = {
"config":
{
#"encoding": "WAV",
"languageCode": "cmn-Hans-CN"
},
"audio":
{
"content": audio_b64str
}
}
# 将字典格式的 voice 编码为 utf8
voice = json.dumps(voice).encode('utf8')
req = urllib.request.Request几点说明:
注释 ① :请求 API 的链接,请替换 ` 你的 API 密钥 ` 。如果你有疑问,或许可以参考 创建 API 密钥 - 使用谷歌 Cloud Speech API 将语音转换为文字 。 audio_file 路径替换为你的本地声音文件路径。
注释 ② :这次上传音频的方式是,将声音文件编码为 base64,把对应的整个字符串放进 json 请求中。如果你执行 print(type(audio_b64)) 就会发现编码后的 audio_b64 是 bytes 类型,所以还需要做一次 decode(),转成字符串。
注释 ③ :先以字典格式保存 json 请求内容,代表声音文件的字符串就在这里放入。
注释 ④ :API 返回的结果保存在 response_str ,如果你直接运行 print(response_str) 就会发现这个字符串可以看做一个有很多 “层” 的字典,要提取出识别结果,需要搞清楚这个字典到底是怎么组成的:
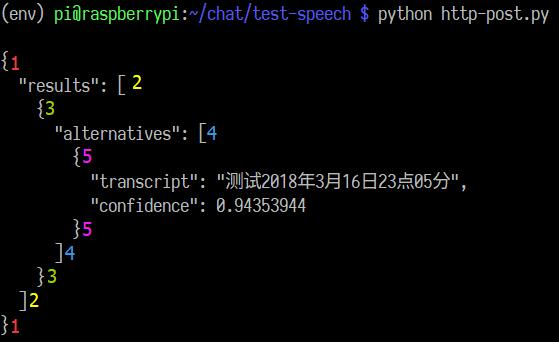
第 1 层:花括号 {} 说明字符串 response_str 在执行 json.loads 后变成一个 “字典”。得到 “字典” response_dic 。
第 2 层:字典中只有一组键 - 值, response_dic['results'] 取出唯一的键 “results” 对应的值。观察这个值,发现中括号 [],说明这个值的类型是” 列表“。
第 3 层:观察列表 response_dic['results'] ,发现列表中只有一项数据,但这项数据又是 “字典” 类型。将其取出,得到 “字典” response_dic['results'][0] 。
第 4 层:字典中又是只有一组键 - 值, response_dic['results'][0]['alternatives'] 取出唯一的键 “alternatives” 对应的值。观察这个值,[] 说明我们得到的结果又是一个 “列表”。
第 5 层:观察列表 response_dic['results'][0]['alternatives'] ,列表中只有一项数据, response_dic['results'][0]['alternatives'][0] 再将这唯一一项数据取出,发现得到的是一个 “字典”,而这次得到的字典中有两组键 - 值,分别取出就是我们要的结果和置信度了。
transcript = response_dic['results'][0]['alternatives'][0]['transcript']
confidence = response_dic['results'][0]['alternatives'][0]['confidence']
小结:
今天介绍的这种方案,获取结果需要的时间比用 API 客户端库要快一些,另外应用了把本地语音编码后放入 json 请求的方式,也能方便后期和录音程序结合在一起使用。但稍有一点缺点是 API 密钥直接暴露在代码中,对实际应用可能会有一些影响。
下一步的目标是和录音功能结合起来,实现自动识别当前录制的语音。
感谢你阅读文章!