前几日讯飞开放平台推出了 WebAPI 接口,恰好最近需要实现一个文字转语音的功能,于是就尝试着用了起来。但不知什么原因,官方文档的 调用示例 一直报错,最后自己照着示例的思路用 python3 重写了一遍。所以这次总结一下在 Python 中使用讯飞 Web API 进行语音合成的过程。
注册讯飞开放平台
首先注册讯飞开放平台:http://passport.xfyun.cn/register
注册完成后进入控制台,在控制台 创建一个新应用 ,填写一些基本信息,注意 ` 应用平台 ` 选择 WebAPI 。
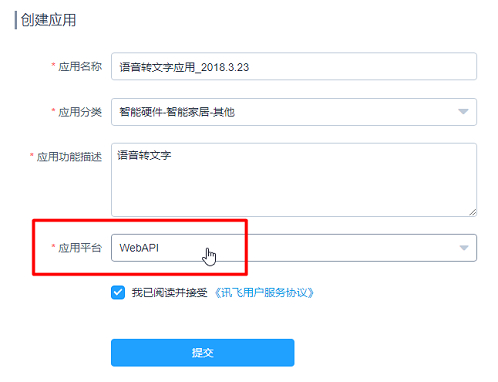
创建完成后,记录下 APPID 和 APIKey ,将在程序中用到。
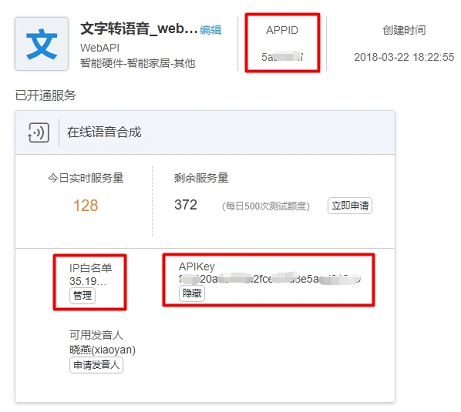
另外,请在 IP 白名单 中添加自己的外网 IP,可以在 http://www.ip138.com/ 查看。(一般来说外网 IP 会常常发生变化,请注意)
在 Python3 中使用讯飞 Web API
先上代码,后面进行必要的说明:
可能提示缺库:pip3 install requests
- 使用 python3 执行
import base64
import json
import time
import hashlib
import requests
# API 请求地址、API KEY、APP ID 等参数,提前填好备用
api_url = "http://api.xfyun.cn/v1/service/v1/tts"
API_KEY = "替换成你的 APIKEY"
APP_ID = "替换成你的 APPID"
OUTPUT_FILE = "C://output.mp3" # 输出音频的保存路径,请根据自己的情况替换
TEXT = "苟利国家生死以,岂因祸福避趋之"
# 构造输出音频配置参数
Param = {
"auf": "audio/L16;rate=16000", #音频采样率
"aue": "lame", #音频编码,raw(生成 wav) 或 lame(生成 mp3)
"voice_name": "xiaoyan",
"speed": "50", #语速 [0,100]
"volume": "77", #音量 [0,100]
"pitch": "50", #音高 [0,100]
"engine_type": "aisound" #引擎类型。aisound(普通效果),intp65(中文),intp65_en(英文)
}
# 配置参数编码为 base64 字符串,过程:字典→明文字符串→utf8 编码→base64(bytes)→base64 字符串
Param_str = json.dumps(Param) #得到明文字符串
Param_utf8 = Param_str.encode('utf8') #得到 utf8 编码 (bytes 类型)
Param_b64 = base64.b64encode(Param_utf8) #得到 base64 编码 (bytes 类型)
Param_b64str = Param_b64.decode('utf8') #得到 base64 字符串
# 构造 HTTP 请求的头部
time_now = str(int(time.time()))
checksum = (API_KEY + time_now + Param_b64str).encode('utf8')
checksum_md5 = hashlib.md5(checksum).hexdigest()
header = {
"X-Appid": APP_ID,
"X-CurTime": time_now,
"X-Param": Param_b64str,
"X-CheckSum": checksum_md5
}
# 发送 HTTP POST 请求
def getBody(text):
data = {'text':text}
return data
response = requests.post(api_url, data=getBody(TEXT), headers=header)
# 读取结果
response_head = response.headers['Content-Type']
if(response_head == "audio/mpeg"):
out_file = open(OUTPUT_FILE, 'wb')
data = response.content # a 'bytes' object
out_file.write(data)
out_file.close()
print('输出文件:' + OUTPUT_FILE)
else:
print(response.read().decode('utf8'))
下面按照代码顺序进行各部分的说明。
APIKey 等参数
在代码开头填好各项参数,方面代码中使用。
API_KEY 和 APP_ID 请替换为上一步创建应用后得到的内容。请不要删除双引号。
OUTPUT_FILE 是最终输出音频的保存路径,根据自己的情况替换。
TEXT 是将要输出为语音的文本。
音频配置参数
Param 是字典格式的音频配置参数,其中 "aue" 可选 raw (生成 wav) 或 lame (生成 mp3),如果修改成 raw 请记得同时修改输出文件的扩展名。
最后需要将配置参数编码为 Base64 字符串:字典类型→明文字符串→utf8 编码→Base64(bytes)→Base64 字符串,具体实现可以参考代码。
音频配置参数的详细说明可以参考 请求参数 - 语音合成 。
HTTP 请求头部
根据 授权认证 - 科大讯飞 RESET_API 开发指南 ,在调用所有业务接口时,都需要在 HTTP 请求头部中配置以下参数用于授权认证:
| 参数 | 格式 | 说明 |
|---|---|---|
| X-Appid | string | 讯飞开放平台注册申请应用的应用 ID(appid) |
| X-CurTime | string | 当前 UTC 时间戳,从 1970 年 1 月 1 日 0 点 0 分 0 秒开始到现在的秒数 |
| X-Param | string | 音频配置参数 JSON 串经 Base64 编码后的字符串 |
| X-CheckSum | string | 令牌,计算方法:MD5(apiKey + curTime + param)。三个值拼接的字符串,进行 MD5 哈希计算(32 位小写)。 |
具体实现参考代码中字典 header
发送请求 & 读取结果
最后使用 requests 库发送 HTTP POST 请求,得到结果。根据响应的 header 可以判断是否合成成功。
若响应头部包含 Content-type: audio/mpeg ,则响应 Body 为音频数据,可写入文件保存。
若合成出现错误,响应头部包含 Content-type: text/plain ,响应 Body 为记载了错误类型的 json 字符串。
返回值的具体说明请参考 返回值 - 语音合成 。
运行结果
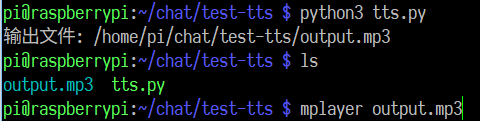
使用几次后,感觉合成语音的断句做得不是很优秀,但响应速度很快,还是比较满意的。
小结
最近使用了几种 Web API,对这类 API 的使用方法也算是有些经验了。最后,现在语音识别、图灵机器人、语音合成都试着做了一遍,下一篇博客将把他们组合起来,实现一个简单的语音助手。
感谢你阅读文章!