概要
使用 Cloud Natural Language API ,可以从文本中提取实体、分析情感、解析文本构成。
此次向导中,我们将针对 Natural Language API 的 3 个方法: analyzeEntities 、 analyzeSentiment 和 annotateText 进行学习。
将要学习的东西
- 构造 Natural Language API 请求,并使用 curl 发送请求
- 使用 Natural Language API 提取文本中的实体,并进行情感分析
- 使用 Natural Language API 对文本进行语言分析(语法、词性等)
- 使用不同的语言构造 Natural Language API 请求
必要的准备
设置和一些说明
根据自己的情况进行设置
还未拥有 Google 账号(Gmail / Google Apps)的情况下,创建账号 是必须的。登录 Google Cloud Platform Console(console.cloud.google.com),创建一个新项目。
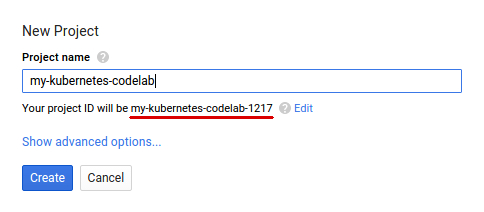
请记住项目名称。任意一个 Google Cloud 项目都拥有唯一的名称(上述的名称已经被使用了,所以实际上无法使用)。
Google Cloud Platform 的新用户将赠与 相当于 $300 的试用金。
启用 Cloud Natural Language API
点击屏幕左上角的菜单图标。

在下拉菜单中选择 [API Manager]

点击 [启用 API] 。

然后,在搜索框中输入「Language」。点击 [Google Cloud Natural Language API]。
点击 [启用],启用 Cloud Natural Language API 。
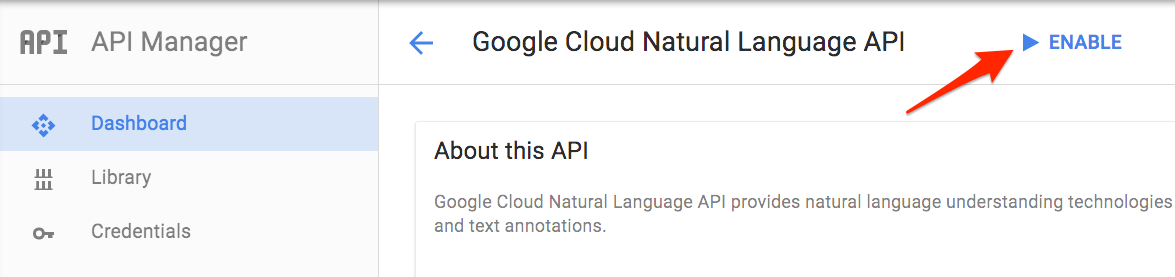
等待数秒,API 成功启用后,将显示如下。

激活 Cloud Shell
Google Cloud Shell 是在云端运行的命令行环境。这台基于 Debian 的虚拟机能够加载任何您需要的开发工具(gcloud、bq、git 等),并提供永久的 5 GB 主目录。这次教程将使用 Cloud Shell 创建对 Translation API 的请求。
点击标题栏右侧的 [激活 Google Cloud Shell] 按钮(>_),启动 Cloud Shell。

Cloud Shell 将在控制台底部的新窗口中打开,并显示命令行提示符。请等待提示符 user@project:~$ 出现。

生成 API Key
你将通过使用 curl 发送一个请求来调用 Natural Language API 。在发送请求时,你需要在 URL 中插入一个生成的 API 密钥。为了创建 API 密钥,让我们点击侧边栏的 [API Manager] 。

然后,在 [凭据] 选项卡中点击 [创建凭据] 。
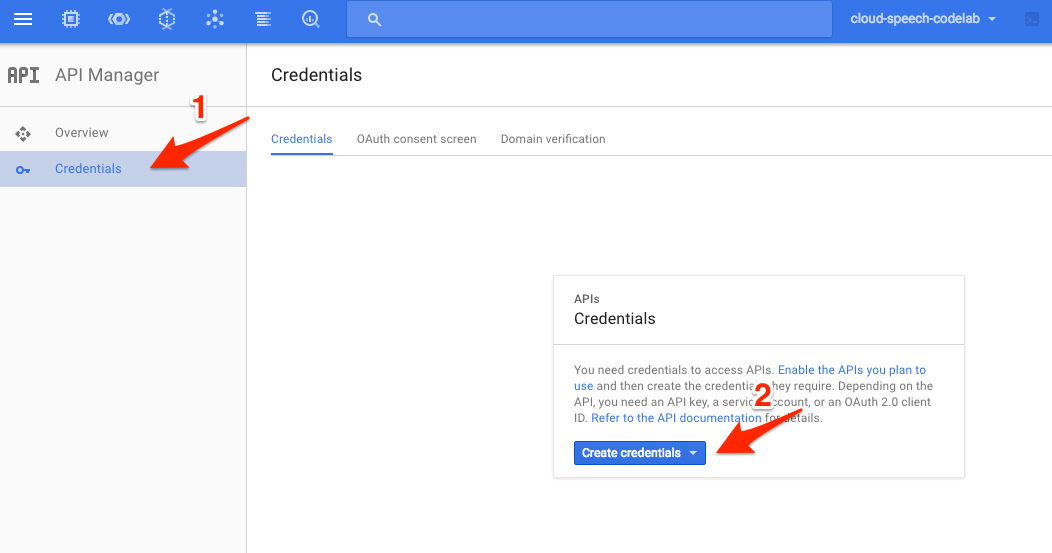
在下拉菜单中选择 [API 密钥] 。
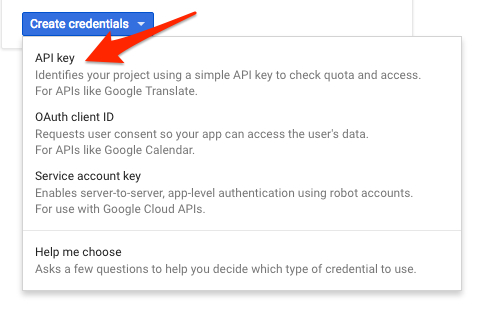
最后,复制生成好的密钥。此密钥将在向导的后半部分中用到。
你已获得 API 密钥,我们将其保存在环境变量中,以便每次调用 API 时不需要重复插入 API 密钥值。你可以将密钥保存在 Cloud Shell 中,下述的 <your_api_key> 请替换成之前复制的内容。
export API_KEY=<YOUR_API_KEY>
构造分析文本中实体的请求
第一个介绍的 Natural Language API 方法是 analyzeEntities 。API 使用此方法从文本中提取出实体(人物、场所、事件等)。为了试用 API 的实体分析功能,我们将引用最近新闻中的以下句子。
LONDON — J. K. Rowling always said that the seventh Harry Potter book, “Harry Potter and the Deathly Hallows, “ would be the last in the series, and so far she has kept to her word.
对 Natural Language API 发出的请求可以事先保存在 request.json 文件中。首先,我们在 Cloud Shell 中生成这个文件。
touch request.json
然后,使用任意一个文本编辑器( nano 、 vim 、 emacs )打开生成的文件。在文件 request.json 中添加如下内容。
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"LONDON — J. K. Rowling always said that the seventh Harry Potter book, ‘Harry Potter and the Deathly Hallows,' would be the last in the series, and so far she has kept to her word."
}
}
在这个请求文件中,保存了即将发送给 Natural Language API 的文本的相关信息。type 属性的值可以是 PLAIN_TEXT 或 HTML 。content 中存放了将要发送给 Natural Language API 分析的文本。Natural Language API 还支持直接发送存储在 Google Cloud Storage 中的文件。直接从 Google Cloud Storage 发送文件时,请将 content 替换为 gcsContentUri ,并将其值设置为云端文件的 uri 地址。
调用 Natural Language API
现在,我们将使用 curl 命令,把请求文件和之前保存好的 API 密钥环境变量一起,发送给 Natural Language API (全放在一条命令里面)。
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" -s -X POST -H "Content-Type: application/json" --data-binary @request.json
你将得到形式如下的响应。
{
"entities": [
{
"name": "Harry Potter and the Deathly Hallows",
"type": "WORK_OF_ART",
"metadata": {
"mid": "/m/03bkkv",
"wikipedia_url": "https://en.wikipedia.org/wiki/Harry_Potter_and_the_Deathly_Hallows"
},
"salience": 0.30040884,
"mentions": [
{
"text": {
"content": "book",
"beginOffset": -1
},
"type": "COMMON"
}
]
}
],
...
...
"language": "en"
}
在响应中,我们可以看到 API 从句子里检测到了 6 个实体(译者:原文是 4 个,但实际运行时得到 6 个,应该是 API 有所改善)。对于每个实体,你将得到实体的 type 、关联的维基百科 URL(如果存在)、 salience (显著性)以及实体在文本中出现的位置的索引。 salience (显著性)是一个 0~1 的数字,指的是该实体对于整个文本的突出性。对于上述文段,「Harry Potter and the Deathly Hallows」具有最高的显著性(译者:原文是「Rowling」,应该是 API 有所改善),这是因为这部作品是文段所表述内容的主题。Natural Language API 也可以识别用其他方式表述的相同的实体,比如说「Rowling」、「J. K. Rowling」和「Joanne Kathleen Rowling」都指向同一个维基百科页面。
使用 Natural Language API 进行情感分析
除了提取实体,Natural Language API 还可以分析文本块的情感。JSON 请求文件与之前的那个具有相同的参数,但这次我们更改一下文本,换成一段具有更强烈情感的内容。请修改 request.json 为如下内容,或者换成你喜欢的文段。
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I love everything about Harry Potter. It's the greatest book ever written."
}
}
然后把请求发送到 API 的 analyzeSentiment 端点。
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" -s -X POST -H "Content-Type: application/json" --data-binary @request.json
你将得到形式如下的响应。
{
"documentSentiment": {
"polarity": 1,
"magnitude": 1.5,
"score": 0.7
},
"language": "en",
"sentences": [
{
"text": {
"content": "I love everything about Harry Potter.",
"beginOffset": -1
},
"sentiment": {
"polarity": 1,
"magnitude": 0.6,
"score": 0.6
}
},
{
"text": {
"content": "It's the greatest book ever written.",
"beginOffset": -1
},
"sentiment": {
"polarity": 1,
"magnitude": 0.8,
"score": 0.8
}
}
]
}
该方法将返回 polarity (极性)和 magnitude (强度)两个值(译者:原文是这两个值,但很明显现在还能看到 score 这个值)。polarity 是介于 - 1.0 ~ 1.0 之间的数值,表示文本消极或积极的程度。magnitude 是介于 0 ~ ∞的数值,与 polarity 没有关系,它表示在文本中表达的感情的权重。权重较大的文本块单是增加长度,其 magnitude 也会变大。上文的 polarity 是 100% 积极。「love」、「greatest」、「ever」这样的单词会影响 magnitude 的值。
分析语法与词性
让我们看看 Natural Language API 的第三个方法:文本注释。让我们进入文本的语言细节。annotateText 方法提供了关于文本情感元素、语法元素的完整细节。使用该方法,可以知道文本中每个词语的词性(名词、动词、形容词等),以及各个单词如何与句子中的其他单词关联(是动词的原始形式,还是用来修饰语句)。
让我们通过简单的文段来使用这个方法。JSON 文件与之前的相似,但在这里我们需要添加一项 features 来告诉 API 你想要执行语法注释。请将 request.json 替换为如下内容。
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling is a British novelist, screenwriter and film producer."
},
"features":{
"extractSyntax":true
}
}
然后把请求发送到 API 的 annotateText 端点。
curl "https://language.googleapis.com/v1/documents:annotateText?key=${API_KEY}" -s -X POST -H "Content-Type: application/json" --data-binary @request.json
响应中,对于句子中的每一个标记(token),会返回以下对象。
{
"text": {
"content": "Joanne",
"beginOffset": -1
},
"partOfSpeech": {
"tag": "NOUN",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "SINGULAR",
"person": "PERSON_UNKNOWN",
"proper": "PROPER",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 1,
"label": "NN"
},
"lemma": "Joanne"
},
让我们详细看看返回值。从 partOfSpeech 可以看到「Joanne」是一个名词。 dependencyEdge 包含可用于创建 依存句法分析树(依存構文木 / Dependency-based parse trees)的数据。这个语法树是一个图表,用来显示句中各单词之间的关系。上述文段的依存句法分析树如下所示。
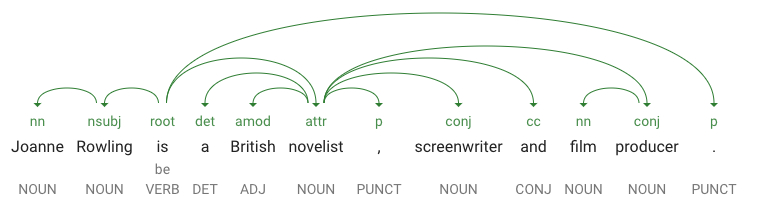
注:使用下面的 demo ,你可以在浏览器中创建自己的依存句法分析树。
上述返回值中, headTokenIndex 是指具有指向「Joanne」的圆弧的标记(token)的索引。文段中的每一个标记(token)都可以看作是数组中的一个单词,「Joanne」的 headTokenIndex 值是 1,表示依存句法分析树中连接了「Rowling」这个单词。 NN (修饰语句 noun compound (名词复合词)的略称)这个标签表示该词在改句子中的作用。「Joanne」是这个句子的主语「Rowling」的修饰词。 lemma 是这个单词的规范化形式。比如,run、runs、ran、running 这些单词的 lemma 都是 run 。lemma 有助于你调查大量文本中某一单词的出现频率。
其他语言的自然语言处理
Natural Language API 还支持其他很多语言的实体分析和语法注释。现在我们以日语为例,尝试进行日语文段的实体分析。
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
}
}
(译者:句意是 “日本的谷歌办公大楼在东京的六本木新城。”)
我们不必告诉 API 这个文段是什么语言,API 能够自动检测出来。我们以相同的方式发送 API 请求。
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" -s -X POST -H "Content-Type: application/json" --data-binary @request.json
你将得到形式如下的响应。
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan",
"mid": "/m/03_3d"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": -1
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": -1
},
"type": "PROPER"
}
]
},
......
......
],
"language": "ja"
}
恭喜!
通过此次向导,我们尝试执行了实体提取、情感分析和语法注释,学会了如何使用 Natural Language API 进行文本分析。
学到的东西
- 构造 Natural Language API 请求,并使用 curl 发送请求
- 使用 Natural Language API 提取文本中的实体,并进行情感分析
- 使用 Natural Language API 对文本进行语言分析(语法、词性等)
- 使用不同的语言构造 Natural Language API 请求
下一步
- 浏览 Natural Language API 文档的 向导。
- 尝试使用 Vision API 、Speech API 。